这里是xml专场!
声明
1 | <?xml version="1.0" encoding="UTF-8"?> |
转义
实体引用
<<>>&&''""
CDATA标签
<![CDATA[ .... ]]>
1 | <?xml version="1.0" encoding="UTF-8"?> |
语义约束
DTD
- 数量限制
<!ELEMENT hr (employee)>只能1个<!ELEMENT hr (employee+)>最少1个<!ELEMENT hr (employee*)>最少0个<!ELEMENT hr (employee?)>最多一个
- 引入DTD文件
<!DOCTYPE 根节点 SYSTEM ”路径“>system代表来自本地
- 属性设置
<!ATTLIST employee no CDATA "">
- 节点所包括的值设置
<!ELEMENT employee (name, age)>
- 变量声明
- <!ELEMENT age (#PCDATA)>
1 | <!-- DTD文档 --> |
1 | <!-- 对应的xml文件 --> |
XML Schema
W3C标准规范 .xsd 比较常用的,但是结构比较复
注意:如果不添加命名空间的话Intellij IDEA会报错
1 | <!-- XML Schema,文件名为hr.xsd,在第二段代码开头需要引入 --> |
对应的xml数据
1 | <!-- hr.xsd.xml --> |
使用dom4j读写xml
对上面的 hr.xsd.xml 进行操作,没什么好说的,就是那个库把xml文件读入进内存封装成Document,然后你就可以像js操作dom一样对它进行操作了
1 | public class App { |
使用xpath解析xml
关于xpath的部分语法如下
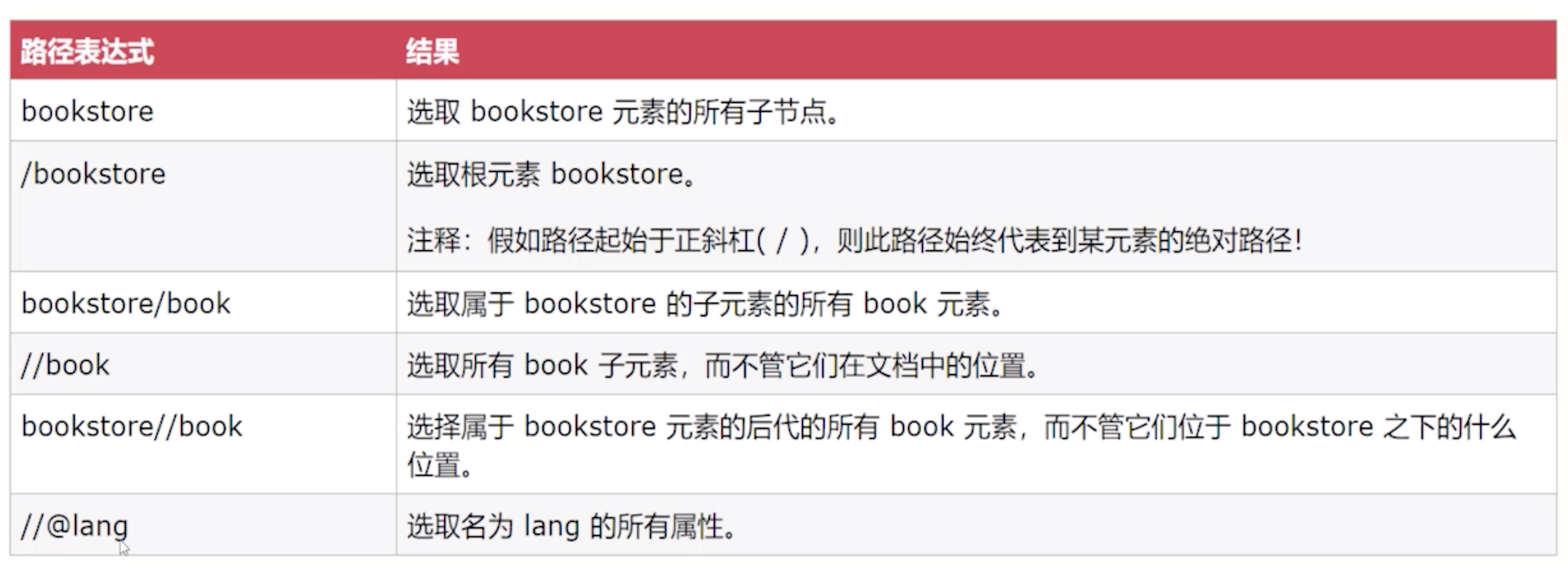
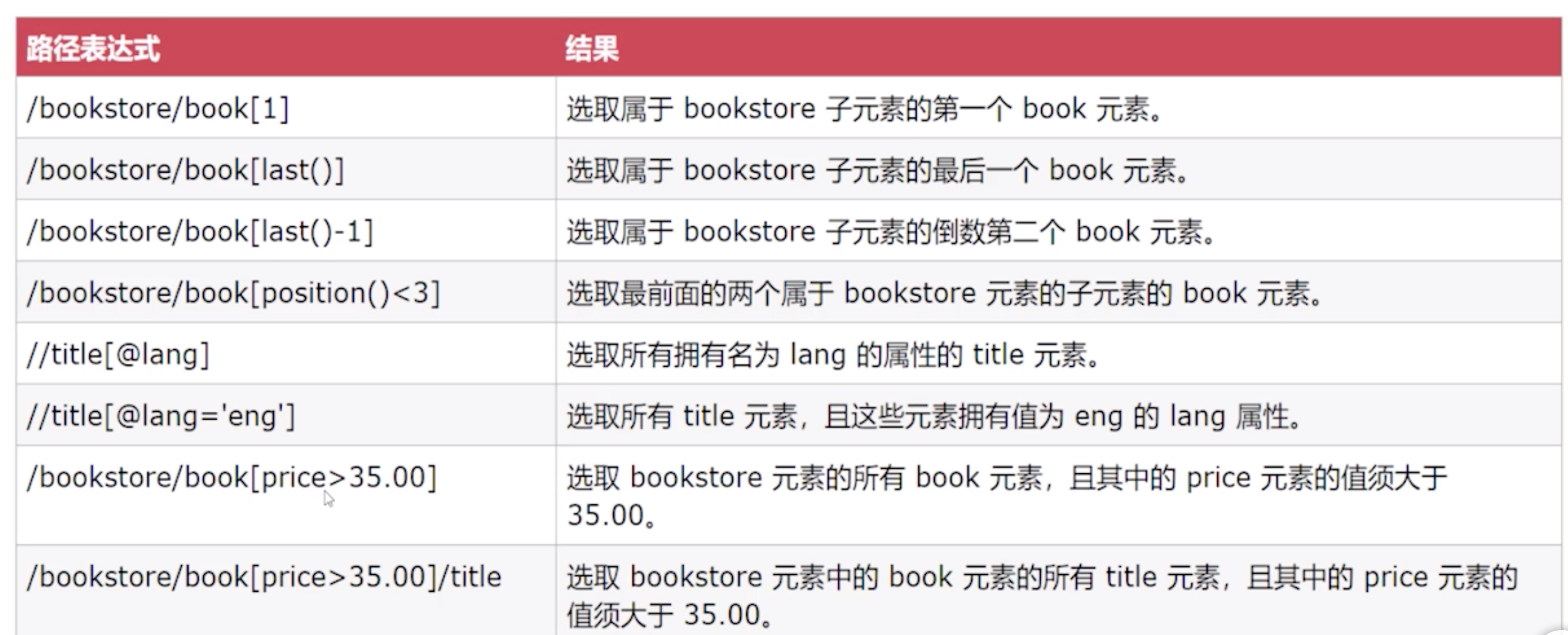
这里需要使用到dom4j和jaxen两个java包,在解析的时候需要注入,如果xml使用了命名空间,需要对其进行额外处理,详见此链接
1 | public class XPathTester { |