最近几个月与大模型应用开发相关的一些总结
之前的事情
我大概是在 2024 年开始接触大模型的。和七八年前接触 web 开发的经历很像,最初都是使用其他人开发的应用,对其中的原理和概念基本不了解。
在日常的工作中使用的的是公司内部提供的一个平台 panda,通过聊天的形式让 gpt/claude/文心给我做一些简单的工作:
写一些简单的代码,例如编写 python 代码读取一个目录下所有的 json 文件并解析
咨询一些技术上的问题,例如 mongo shard 的新节点同步数据的流程
在代码开发的过程中,使用到了公司提供的基于大模型的代码补全/纠错插件 comate 。由于这个插件的补全效果还是挺不错的,现在已经习惯了写了一半代码后,等 comate 给我补全剩下的内容,以至于回到自用电脑上写代码,在没有 comate 的情况下,都有点不太会写代码了。
在这期间也接触到了其它一些基于大模型开发的应用,例如 Perplexity,在向它提问后,它会主动地对问题进行拆解,然后对于每个子问题,在网上搜索相关资料,最终给出总结。
我在整个 2024 年的工作都是围绕着离线建库架构迁移开展的,到年末快告一段落的时候,组长给我分配了一个和大模型相关的新的方向。
从 2023 年到 2024 年,组内其它的同事参与建设了一个智能助手的项目,利用大模型的能力实现了如下功能:
文档问答:基于组内沉淀的文档,对于用户在离线建库领域提出的问题进行回答
工具调用:根据用户的需求,调用工具来完成简单的需求
这个项目目前已经处于无人维护的状态。对于文档问答功能,在实现的时候调用的是一个千帆的接口来完成文档的检索和总结,但是目前处理接口返回的数据异常,且相关负责同事已经记不清这个接口在千帆上的管理页面了。对于工具调用,在实现的时候使用的模型是 gpt ,成本略高,且工具调用效果一般。组长希望我可以接手这个项目,作为智能化线条的一部分,利用最新的技术进行重构。
对于我个人而言,对大模型相关的技术也是挺感兴趣的,借着这个机会,在学习相关知识的同时,也能有一个具体的场景进行实践,并且由于是上级安排的探索性质的方向,也即可以在工作时间进行知识学习以及编码开发,所以实际上算是公司给你付费学习?
回想起本科接触 web 开发时,由于缺乏实践的场景,有很长一段时间只是看相关的技术书籍以及文档,非常枯燥,差点失掉了兴趣,万幸后面报了一个网上极客学院的训练营,虽然他授课的内容质量不高,但是有一个完整的只是体系,并提供了大量的项目实践,且有专门的人 review 代码,才使得我的 web 开发的能力有了质的提升。那一阶段的经历算是我第一次真正意义上从零到一的自学。在后续对于新技术的学习上,我都尽量保持着实践优先的原则。
基础入门
2025 年 Q1 的工作中,主项是 2024 年建库架构迁移的收尾,所以在 Q1 上半段进行收尾工作时,利用周末的时间先进行了与大模型开发相关的基础知识的学习。这一阶段的学习资料主要是极客时间的课程「程序员的 AI 开发第一课」。课程里有一个完整的知识体系,并且每一个知识点都配有代码样例,感觉还是不错的。
提示词
第一个关键概念是提示词(prompt)。实际上在和模型聊天的时候,用户发送给模型的文本就是提示词。模型会根据提示词生成对应的回答文本。
在给人安排工作任务时,只有把任务的内容描述的足够细致,执行任务的人才可以理解并正确地完成,例如在安排任务的时候,需要说明任务的背景、任务的总目标、可以做怎样的拆解、可以使用哪些工具、得到最终结果的格式等。
和大模型交互也是类似的,如果想让模型的回答更加精确,需要使用一些特定的提问格式,提供给大模型足够多的信息,例如定义角色 + 背景信息 + 任务目标 + 输出要求。并且就像是和人协作时,事前需要多次进行沟通对齐,事中需要多次检验子任务完成情况以及整体进度,事后需要验收一样,在和大模型交互时,需要根据模型执行的结果多次校准和优化提示词的内容,以达到最优的效果。
chat api
大模型的供应商提供了和大模型进行交互的 http 接口,开发者可以基于这个接口构建多种多样的应用,最常见的就是大模型聊天应用。
和一般 http api 不同的是,为了降低用户可感知的延迟,大模型 chat api 接口使用了 sse 技术,流式返回大模型相应的 token,让用户可以感知到的响应延迟从模型完全输出结果提前到模型输出第一个 token。
agent
在我的理解中,利用大模型的能力来完成特定任务的功能模块,就可以被称为 agent。
agent 封装了和模型交互的流程,并作为完成一个任务的其中一个环节。为了更好地让模型来完成特定的任务,agent 内部预制了系统提示词(system prompt),请求大模型时的 prompt 为系统提示词 + 当前用户提示词。
由于当前在调用大模型时一般为纯 http 接口,大模型侧不维护对话的上下文,所以如果有多轮对话的需求,需要由 agent 负责统一管理一次对话的上下文,以及在组装发给大模型的完整的 prompt 时,对历史对话进行裁切,在节约 token 的同时,避免大模型丢失重点。
ReAct
一般来说,一个领域都会有一些最佳实践,例如编程领域的设计模式。在大模型应用开发中,也出现了一些优秀的范式,从而使得模型能更好地完成任务,ReAct 就是其中之一。
通过 system prompt,让大模型在执行任务时,经历 思考 -> 行动 -> 观察 -> 思考 -> … 这一流程,以实现大模型对一个任务的拆解、子任务的执行以及自我检查执行结果。在行动阶段,可以提供给大模型一系列的工具,让它来执行 tool call 来获取额外的信息或者执行子任务。
RAG
全称为 Retrieval-Augmented Generation,这也算是一种大模型应用的执行范式。当用户在向大模型提问时,如果这个问题依赖某一特定领域的知识,或者对时效性要求较高,那么就需要在向大模型发起请求时,在请求的 prompt 中添加上这些知识,并告诉大模型需要结合提供的知识来进行回答。
大模型应用开发 lib 和框架
之前看过一个形象的比喻,lib 是盖房子的工具,例如锤子,而框架是房子的脚手架。lib 可以使模块的一个功能更为高效地实现,而框架定义了整个模块应该如何实现。在大模型应用开发领域,一个流行的 lib 和框架分别是 python 库 openai 和 langchain 框架。
实际上在极客时间的文章中,并没有一开始就上来介绍 lib 和框架的使用,而是通过裸调 openai http api 的方式,实现了一个简单的聊天机器人,通过这个 demo,可以清晰地展示出在交互时 request 和 response 的 body 的 json 格式,而 lib 无非就是对这个调用流程的封装以及增加一些切面。
langchain 框架则是对大模型应用执行流程做了抽象,抽象为了类似于 linux 的 pipe 调用形式,模型调用作为其中的一个环节加入到调用链中。在这个调用链上可以动态增减组件,例如提示词模板、对话管理器等。一个样例为 chain = template | history_msg | trim_msg | model | parser ,然后执行 chain.invoke(messages) 或 for msg in chain.stream(messages): 实现了一次应用业务逻辑的执行。
我按照文章中的 demo,使用 langchain 框架实现了一个最简单的聊天机器人时的感觉,和七八年前学习 http server 的时候用 nodejs 实现第一个简单的 MEAN (MongoDB + Express.js + Angular + Nodejs)服务时的感觉差不多,了解了一种全新的领域以及开发范式。
文档问答模块重构
背景
服务号「 搜索离线建库help」 对于问答问答的场景,原服务直接调用了千帆的接口,且这个接口目前调用出错。实际上原先这个接口返回的结果也不是特别好,于是决定重新搞一个可控的问答模块。

选型
其它团队建设过一个智能问答机器人,看着效果不错。咨询了相关负责的同学,是基于自建的 RAG 服务实现的。
RAG 的流程简单来说是:
用户提问
使用用户的问题检索关联的文档
将用户的问题和检索到的文档内容一起发给大模型
大模型结合文档的内容对问题进行解答
也就是补充了额外的知识给大模型。正好极客时间上有一门「RAG 快速开发实践」的课程,系统地介绍了 RAG 的实现细节,所以我就边学着课程,边利用学到的技术来重构文档问答模块。
检索数据生成
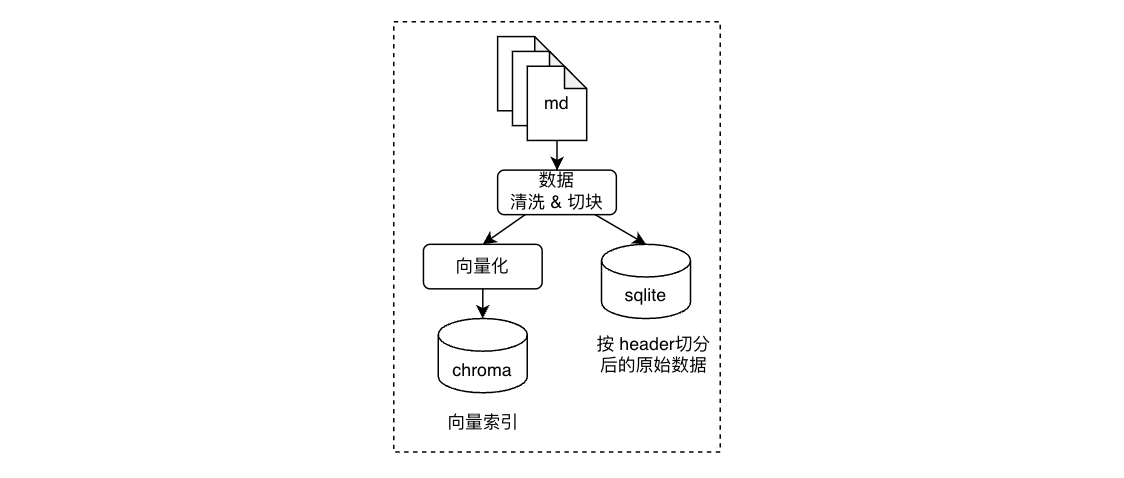
简单来说,就是将原始文档转换为 markdown 的形式,并按照一定的规则进行第一次切块,切块后的原始数据存入到 sqlite 中。接着进行更细粒度的切块,并将切块结果向量化后,存入 chroma 向量数据库中。
按照一般 markdown 文档向量化的流程,首先先基于标题进行第一次切割,这里使用到了 langchain_text_splitters.MarkdownHeaderTextSplitter库进行处理。
按照标题切块的结果列表中,每一个块的 meta 信息中都会存有它所在的标题信息,另外我还为每一个块的 meta 信息中添加了一个唯一的 id 以及它来自的 markdown 文件 id 信息,用于在召回阶段使用。meta 信息的样例如下:
1 | {'Header_2': '快速开始', 'Header_3': '请求示例', '__page_id_key': 'mongo_restapi_doc.md_page_39fc7ddb-8322-472e-8def-ae819b556d7d', '__file_id_key': 'mongo_restapi_doc.md'} |
这部分数据会落一份到本地的存储 sqlite 中,使用的 key 为 __page_id_key,value 为序列化为字符串的块数据。由于切块的库 langchain_text_splitters是在 langchain 体系下的,切块的结果为 langchain_core.documents.Document类型,所以可以调用 langchain 提供的工具进行序列化和反序列化
1 | from langchain_core.load import dumps as langchain_obj_dumps |
基于存量文档的现状,其中存量大量的无用文本,包括:
图片链接
样例代码(这个待商榷,目前是删除的)
网页(文档)链接
在召回阶段进行向量匹配的时候,无用数据的存在会影响召回的效果(自己的感觉,暂时没空做对比实验 … ),所以在二次切块前,会将上述的文本从块中删除。
需要注意的是,如果一个标题块中文本在清洗完被完全清空了,例如原块中只有代码,那么会为其添加这个块最小标题的内容。例如一个块来自于一个三级标题,如果这个块的内容被清空了,那么就会为其补充上三级标题的内容。
为了提升召回时的精度,会对第一次切块得到的结果进行二次切块,这次切块是基于文本的长度,使用 langchain_text_splitters.RecursiveCharacterTextSplitter进行处理。目前的配置是每 100 个字符切一个块,相邻两个块之间重合的字符为 30。
在梳理存量的文档时,我发现文档的一个特点是,一般标题中表达的是问题的现象,而正文中是问题的解决方案,类似于下面这样:
1 | # section1 |
所以个人感觉,需要将标题的内容添加到最终的切块结果中,这样应该可以提升召回的效果。最终得到的块内容格式为 "\t".join([ 多级标题 ... ]) \t 切块文本 。样例如下:
1 | 块内容:慢查询屏蔽 新增的功能 判断每次请求where字段中每个键是否是索引键,如果不是则屏蔽 |
切块数据存储与更新
为了尽快实现一版可用的简易 rag 服务,目前采用的是数据全量更新的方式,也即参考批量库的建库流程,每次都生成全量的数据(批量建库),然后通知(传库) rag query 服务切换数据地址(换库)。当前因为基本没有人使用,所以就是简单的先停 query 服务,然后更新 chroma 和 sqlite 数据,最后启动 query 服务。
对于第一次切块得到的标题粒度的数据,存入 sqlite 中,用于在召回阶段返回给用户以及发给大模型进行总结。
对于第二次切块得到的数据,使用本地 embedding 模型 bge-small-zh-v1.5进行向量化后,存入 chroma 中,用于在召回阶段和用户 query 进行向量匹配。
query 召回
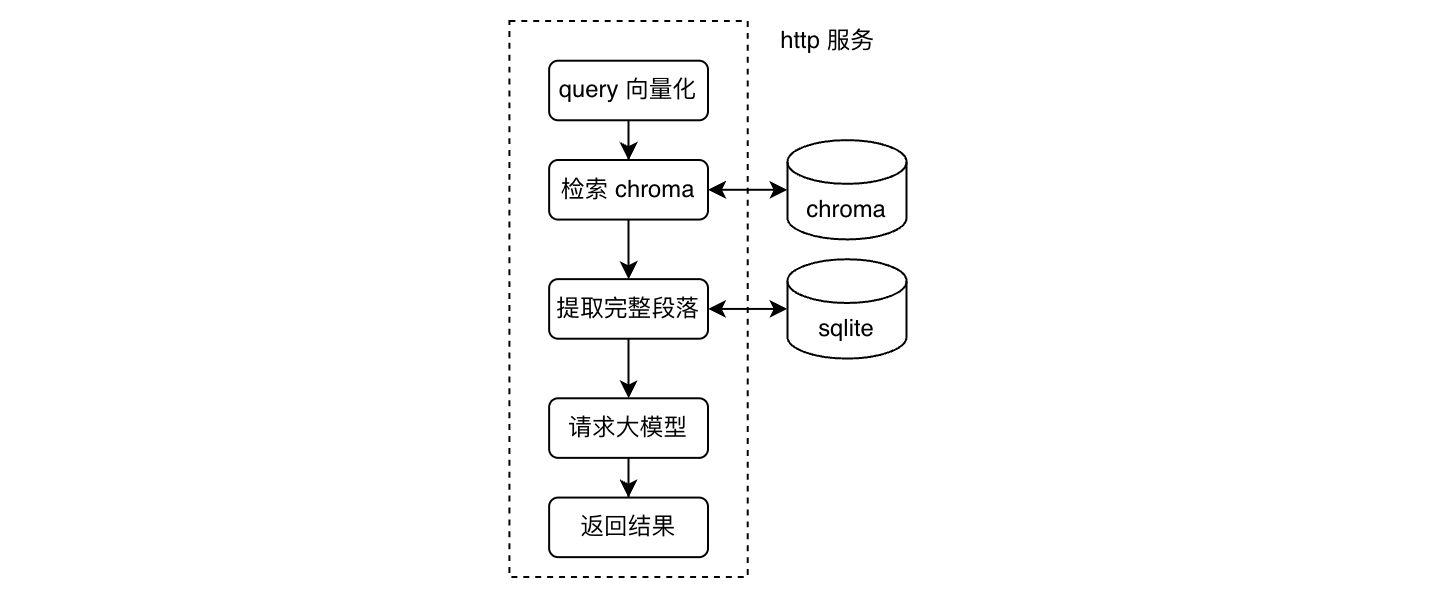
在收到用户的 query 后,会将 query 使用 bge-small-zh-v1.5向量化后,调用 chroma 的接口进行向量召回,召回 topk 的结果。这里召回的是第二次切块后的内容,样例如下,其中 chunk_a 、chunk_b 和 chunk_d 来自于第一次按照标题切块得到的 page_1_xxxxx ,chunk_c 来自于 page_2_yyyyy,chunk_e 来自于 page_3_zzzzz 。
1 | chunk_a metadata: { '__page_id_key': 'page_1_xxxxx' } distance: 0.11 |
那么这里按照标题块粒度生成最终的排序结果,并从 sqlite 中标题块对应的内容读取出来,作为最终的结果。这里之所以使用标题块粒度作为最终结果的原因是,存量的文档中,一般标题下正文的内容都不是特别多,不会出现大几千字的情况。
1 | page_1_xxxxx |
这里会将上一步中得到结果的 topk 发给大模型,让其进行总结。目前只发了首位的结果。
prompt 模板如下:
1 | 你是问答任务的助手,只能使用以下上下文来回答问题.上下文分为多个段落,每个段落的内容为markdown格式.和问题相关的优先级按照段落先后顺序从高到低排序.保持回答的简洁,回答内容需要符合markdown语法规范,并根据上下文补充代码样例以及图片.如果你根据上下文无法得出回答,就说请参考下列文档. |
请求样例如下:
1 | 你是问答任务的助手,只能使用以下上下文来回答问题.上下文分为多个段落,每个段落的内容为markdown格式.和问题相关的优先级按照段落先后顺序从高到低排序.保持回答的简洁,回答内容需要符合markdown语法规范,并根据上下文补充代码样例以及图片.如果你根据上下文无法得出回答,就说请参考下列文档. |
目前由于模型对于发给它的上下文的总结并不是特别准确,所以在最终返回给用户的结果中,也会加上首位的结果,以及 topk 的原始文档链接及其中的标题,大概格式如下
1 | 构建最终模型响应的结果, 主要做的是: |
样例展示
文档段落返回:

模型总结:
关联文档:
总结
对于已经接入的存量文档,做了一个简单的评估,文档链接召回成功率 90%,文档段落召回成功率 70%,感觉还算不错。不过对于一个工程项目来说各个模块的功能比较简略,但是对于两周不到搞出来的项目来说,至少算是基本可用,应该有 60 分的水平了。并且接着这个机会,熟悉了 RAG 的基本流程,并且还额外学习到了向量检索相关的知识。
对接建库大脑
背景
当前离线建库的一些信息会在建库大脑平台上展示,主要包含离线建库 2.0 的库种信息及其相关建库任务的执行信息。平台上展示的信息有限,希望有一种便捷的方式可以在查询建库信息的时候起到辅助的作用,例如输出某个库种某次重建任务的执行情况。目前实现的一版方案是基于大模型 tool call 的能力,在理解用户需求后,指定执行计划,在调用对应的查询工具后,对结果进行总结,最终输出结果。算是一种实验性质的功能实现。
tool call
现阶段给来带来最大震撼的大模型的能力就是 tool call 了。简单来说,就是提供给大模型一系列工具,描述其作用以及调用参数,它就能根据用户提出的问题给出需要调用的工具的名字以及参数的值。也就是说,不同于调用 API/CLI/GUI 时,用户需要明确选择调用的工具以及填写对应的参数,现在只需要通过自然语言描述需求,大模型就可以基于需求生成调用工具的参数了,这简直是接口调用模式的一大飞跃。
并且基于类似于 ReAct 的模式,大模型甚至可以自主调用多个工具来完成需求,这意味着只用给大模型提供几个最基础的工具,它就可以自行编排各个工具执行的先后顺序以及参数,并且甚至可以在调用工具的过程中根据之前工具返回的结果,自主发现错误并做调整。
不过我个人认为,目前这种模式主要还是使用 Get 类型的工具比较靠谱,因为如果工具执行结果不可逆,那么如果模型执行工具调用存在问题,就会对整个系统造成影响。错误的响应有可能比不响应更有危害。
eino 框架
基于 golang 的大模型应用开发框架,目前我个人觉得它的优势在于
基于 golang,强类型
抽象较好,业务逻辑和架构逻辑解耦
支持切面
功能点1:对一个模型的访问方式做了统一的抽象。目前提供了几个典型的模型 API 实现,包括 OpenAI 和 Ollama
1 | // ChatModel support openai and maas. |
功能点2:对一个请求处理的流程及流程中的节点做了统一的抽象,支持编排。目前提供了两个和大模型交互的典型流程:ReAct 和 Multi Agent
1 | // Runnable is the interface for an executable object. Graph, Chain can be compiled into Runnable. |
功能点3:支持切面能力,可以较好地支持通用逻辑注入,例如 trace
1 | type HandlerBuilder struct { |
基于 eino 的多轮工具调用
v1
在对接建库大脑时,将它提供的一些 http 接口封装为了 tool 供大模型在回答问题时进行工具调用。第一版的实现借鉴了 eino 的 plan - exec 执行流程,介绍文章见 DeepSeek + Function Call:基于 Eino 的“计划——执行”多智能体范式实战,流程如下
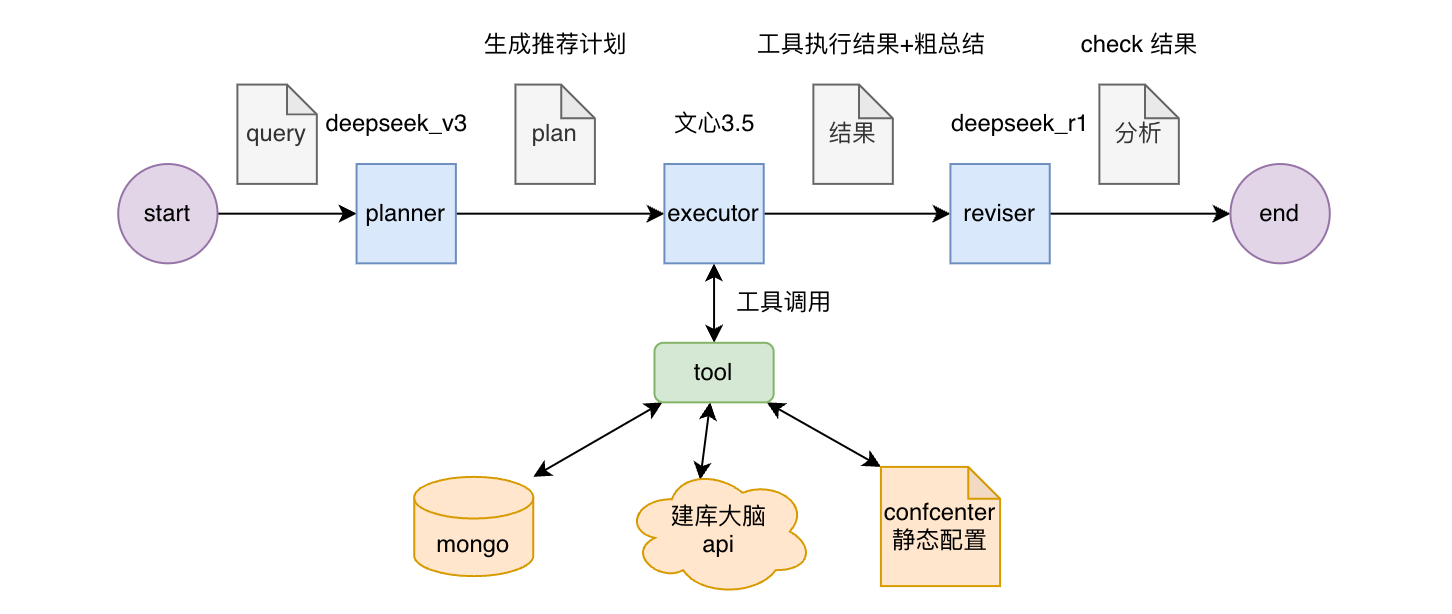
大致的执行流程如上图所示:
首先,Planner 收到用户的提问后,会基于提问和可使用工具的简略信息,列出一个执行计划表。
然后,Executor 会根据用户的提问、Planner 生成的执行计划表以及可使用工具的详细信息进行多轮工具调用。
最后,Reviser 会基于 Executor 调用工具的执行结果以及其他输出进行总结,核实这些内容是否可以解答用户的提问。
由于这里的场景较为简单,删去了原执行流程中 reviser -> executor 的部分。
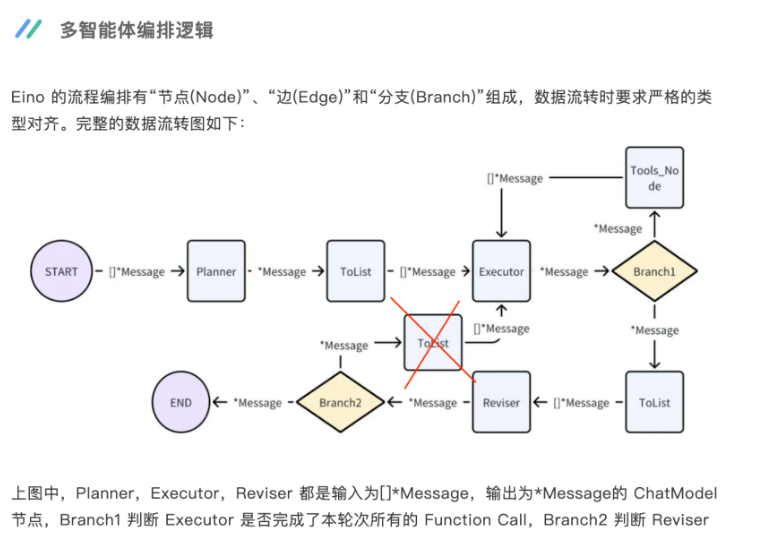
在模型的选择方面:
对于 Planner,由于目前需要执行的工具不多,且场景不是很复杂,没有必要使用 r1 的深度思考能力,所以使用 v3
对于 Executor,文心 3.5 执行 function call 的效果实测下来已经足够好了,没有必要升级为文心 4.0,所以使用 3.5
对于 Reviser,由于需要对 Executor 输出的数据进行分析,为了提升分析结果的准确度,所以这里使用了 r1 的深度思考能力
实测下来执行结果还算不错,但是在后续和组长交流时,他建议能否让 planner 一次只给 executor 一个子任务,而非整个计划。因为问题是,如果 executor 模型执行能力有限,那么它不一定能根据彻底执行执行计划的步骤,以及补全计划中的细节,有时甚至放弃执行了。
v2
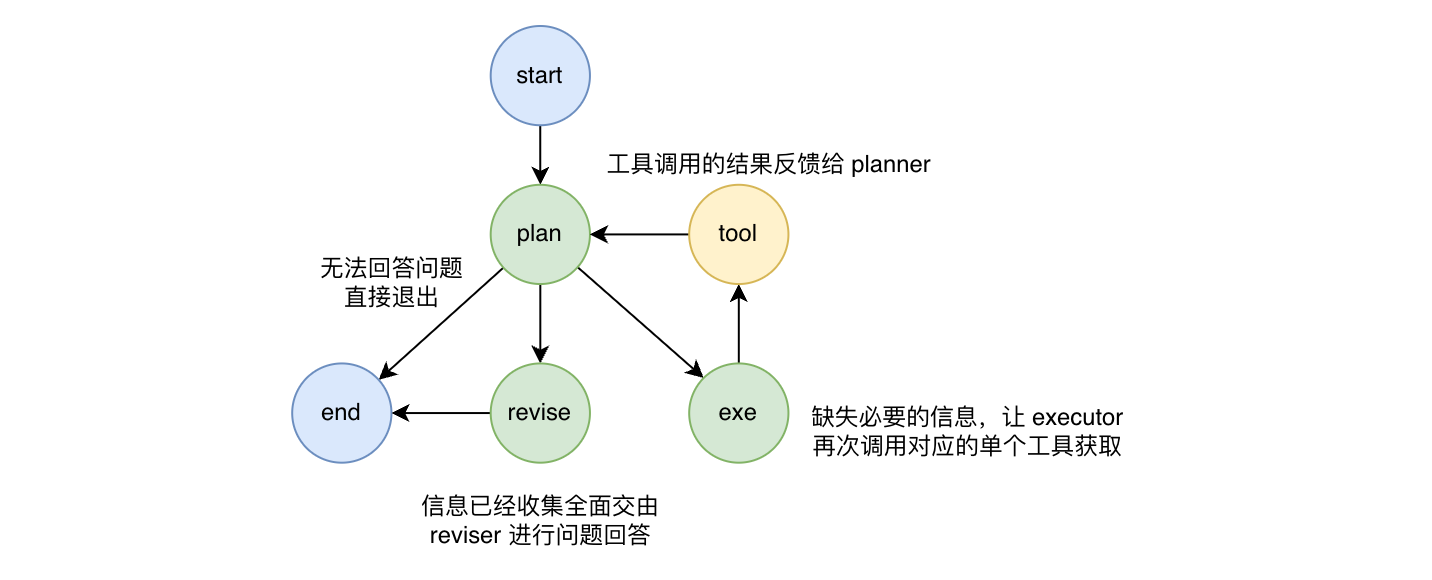
对上述流程做如下改造:
planner
负责分析用户的问题,为问题的解答准备额外的数据
为了获取需要的数据,planner 一次生成一个工具调用的指令,这个指令交给 tool_executor 执行
tool_executor 如果执行出错,planner 会根据出错信息进行反思
如果解答问题需要的数据已经收集全了,那么就交给 reviser 进行总结,reviser 可以使用有深度思考能力的模型
需要有工具的入参和出参详细信息,这样方案指定能准确一些
tool_executor
它接受的上下文只有 planner 生成的最后一条指令
不关心用户提出的原始问题。因为这个指令是细化过的,更加明确,所以弱一些的模型也可以执行
如果执行失败,透传错误信息给 planner
如果执行成功,返回给 planner 的只有工具的入参和出参
reviser
- 对 planner 的信息进行总结
改造后的执行流程大致如下:
eino 框架编排细节
planner 部分 prompt
1 | 你会收到用户关于搜索离线建库单个buildspace及其相关信息的提问。你的工作是仔细倾听用户的问题,结合之前执行的历史记录,思考当前需要获取和分析哪些信息,形成一个分步骤的严谨的解决思路,或者对之前的解决思路进行调整。步骤拆分的尽量细致,最终输出你任务需要执行的下一步内容。 |
executor 部分 prompt
1 | 你会收到关于工具使用的建议,你**必须执行建议中提到的API工具**。如果你认为建议中的工具有误,则使用简练的语言说明原因,格式为:"工具调用失败,简略原因: xxx" |
reviser 部分 prompt
1 | 你会收到用户关于搜索离线建库buildspace及其相关信息的提问,以及已完成的各步骤及其结果。你的工作是汇总执行过程中获取的所有信息,最终产出用户问题的回答。如果用户提到了重建任务,这个指的是名为resched-job的job。有下述输出选择: |
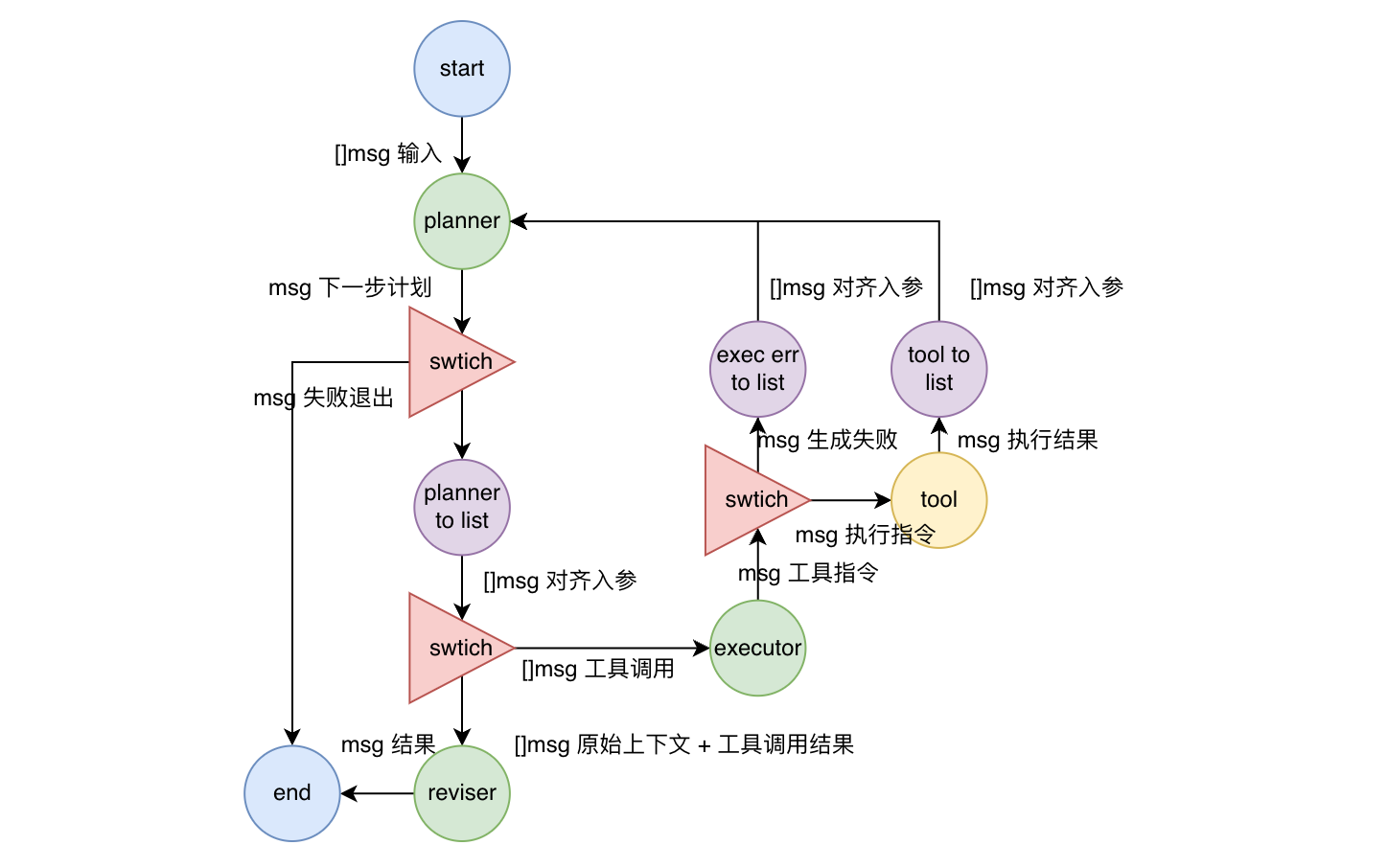
在使用 eino 框架的编排时,在跳转时添加的对应的判断
1 | // planner -> planner_to_list |
最终执行时的效果非常有意思,一个样例如下:
首先 planner 告诉 executor 要调用工具 1,但是 executor 在调用时,由于缺少上下文信息,导致参数填的有问题,最终工具返回结果不符合预期。然后 planner 根据工具调用的结果进行了反思后,调用工具 2 获取了上下文信息,并告诉 executor 调用工具 1 时使用对应的参数,最后 executor 调用工具 1 成功了。
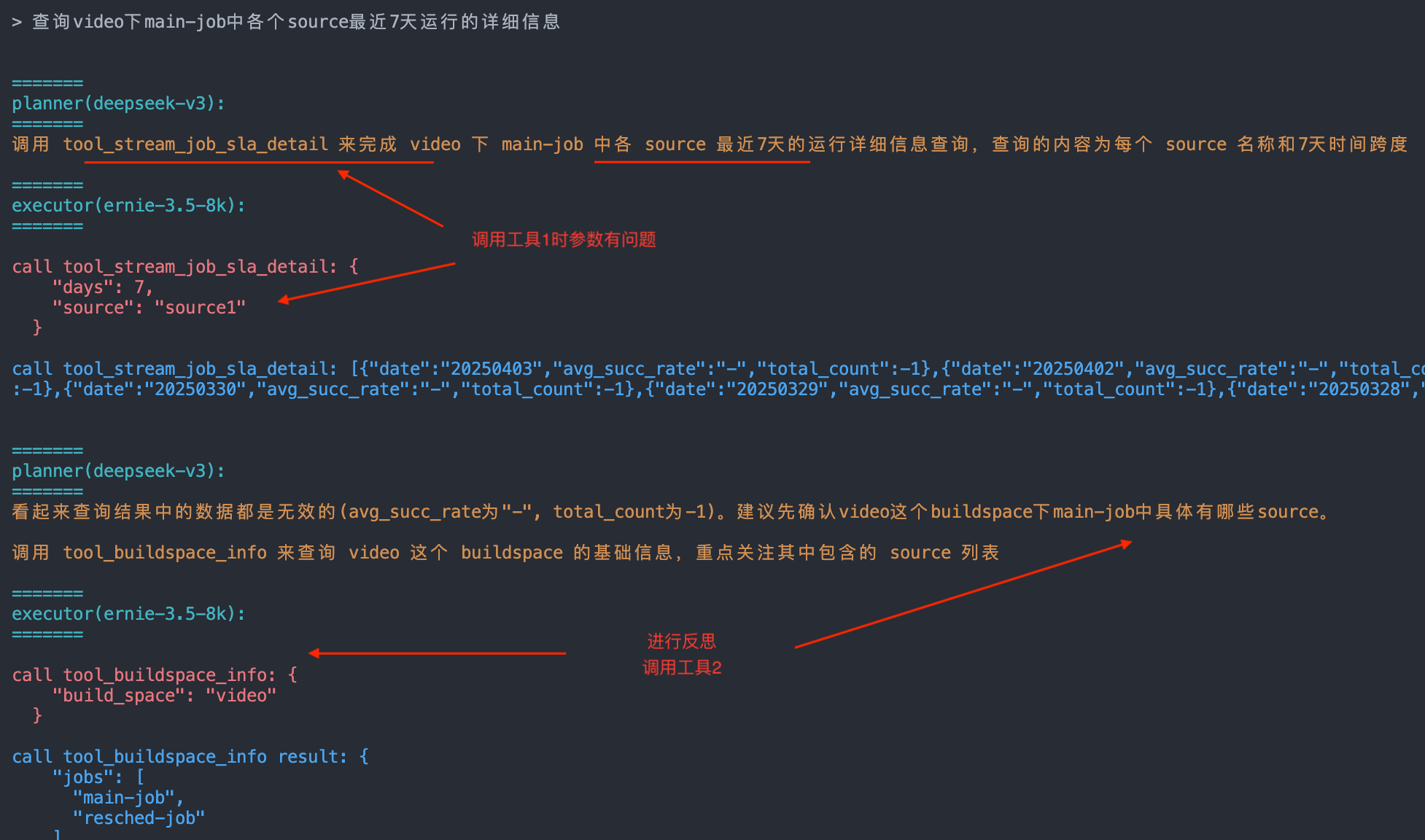

总结
使用 eino 框架和 golang 代码进行开发很大程度上减少了心智负担,可以专注于业务逻辑和切面逻辑的开发,而不用关心执行拓扑之间联动的细节以及各个节点输入输出的类型。虽然在进行代码编写时,相较于 python,会多出来不少内容,因为需要显示定义各个接口的类型,但是在完成编码时,心里是非常踏实的。另外,好几年没关注 golang 了,没想到现在居然已经支持泛型了,终于不用将框架抽象接口的类型定义为 interface{} 了。
后续的计划
毕竟我所在的组主要负责的是搜索离线建库相关的业务,这个智能化线条只能算作是架构演进的一部分,并且还是探索性质的,优先级较低,所以如果后续有新的高优业务插入,那么也只能暂时 hold 了。
到目前接触大模型应用开发的时间是两个多月,整体感觉这个领域能做的事情还是挺有意思的,问题是目前主要还是缺乏明确的跟已有业务结合的落地场景,上述段落中提到的 RAG 和 tool call ,基本都有成本更低的替代品。例如对于 RAG ,由于当前组内存量的文档并不多,实际上只要将其分门别类整理到一个统一的知识库下,需要的时候直接在知识库里按照关键词搜就可以了,而对于后者,由于目前查询的种类并不是很多,直接封装对应的 http api 接口 + 简单 web 界面也行。不过对于我个人来说,使用新的技术实现上述需求,通过实践可以加深对这些技术的理解,万一后面哪天真的有某个场景可以落地,也可以有能力可以感知到。
如果 2025 Q2 没有高优业务插入的话,有两个方向:
进一步补充大模型应用开发的相关知识,并尝试寻求落地的场景。不过这块目前没有找到合适的资料,还在探索中。
学习与大模型原理相关的知识,先从周志华的「机器学习」开始。